
Không có gì đáng ngạc nhiên, tại Rewind ở đây, chúng tôi có rất nhiều dữ liệu cần bảo vệ (trị giá hơn 2 petabyte). Một trong những cơ sở dữ liệu chúng tôi sử dụng được gọi là Elasticsearch (ES hoặc Opensearch, như nó hiện được biết đến trong AWS). Nói một cách đơn giản, ES là một cơ sở dữ liệu tài liệu tạo điều kiện cho kết quả tìm kiếm nhanh như chớp. Tốc độ là điều cần thiết khi khách hàng đang tìm kiếm một tệp hoặc mục cụ thể mà họ cần khôi phục bằng cách sử dụng tua lại. Mỗi giây của thời gian chết đều có giá trị, vì vậy kết quả tìm kiếm của chúng tôi cần phải nhanh chóng, chính xác và đáng tin cậy.
Một xem xét khác là khắc phục hậu quả thiên tai. Là một phần của quy trình chứng nhận Hệ thống và Kiểm soát tổ chức cấp độ 2 (SOC2), chúng tôi cần đảm bảo rằng chúng tôi đã có kế hoạch khắc phục thảm họa đang hoạt động để khôi phục dịch vụ trong trường hợp không may toàn bộ khu vực AWS không hoạt động.
“Cả một khu vực AWS ?? Điều đó sẽ không bao giờ xảy ra!” (Ngoại trừ khi nó đã xảy ra)
Bất cứ điều gì đều có thể xảy ra, mọi thứ đều có vấn đề và để đáp ứng các yêu cầu SOC2 của chúng tôi, chúng tôi cần phải có một giải pháp phù hợp. Cụ thể, những gì chúng tôi cần là một cách để sao chép dữ liệu của khách hàng một cách an toàn, hiệu quả và tiết kiệm chi phí sang một khu vực AWS thay thế. Câu trả lời là làm những gì Rewind làm rất tốt – hãy dự phòng!
Hãy đi sâu vào cách hoạt động của Elasticsearch, cách chúng tôi sử dụng nó để sao lưu dữ liệu một cách an toàn và quy trình khắc phục thảm họa hiện tại của chúng tôi.
Ảnh chụp nhanh
Đầu tiên, chúng ta sẽ cần một bài học từ vựng nhanh. Các bản sao lưu trong ES được gọi là ảnh chụp nhanh. Ảnh chụp nhanh được lưu trữ trong kho ảnh chụp nhanh. Có nhiều loại kho lưu trữ ảnh chụp nhanh, bao gồm cả một loại được hỗ trợ bởi AWS S3. Vì S3 có khả năng sao chép nội dung của nó sang một thùng ở khu vực khác, nên nó là một giải pháp hoàn hảo cho vấn đề cụ thể này.
AWS ES đi kèm với một kho lưu trữ ảnh chụp nhanh tự động được kích hoạt sẵn cho bạn. Kho lưu trữ được định cấu hình theo mặc định để chụp ảnh nhanh hàng giờ và bạn không thể thay đổi bất kỳ điều gì về nó. Đây là một vấn đề đối với chúng tôi vì chúng tôi muốn một ảnh chụp nhanh hàng ngày được gửi đến một kho lưu trữ được hỗ trợ bởi một trong các nhóm S3 của chính chúng tôi, được định cấu hình để sao chép nội dung của nó sang một vùng khác.
 Danh sách các ảnh chụp nhanh tự động GET _cat / snapshots / cs-automatic-enc? V & s = id
Danh sách các ảnh chụp nhanh tự động GET _cat / snapshots / cs-automatic-enc? V & s = id
Lựa chọn duy nhất của chúng tôi là tạo và quản lý kho lưu trữ ảnh chụp nhanh và ảnh chụp nhanh của riêng mình.
Duy trì kho lưu trữ ảnh chụp nhanh của riêng chúng tôi không phải là lý tưởng và có vẻ như rất nhiều công việc không cần thiết. Chúng tôi không muốn phát minh lại bánh xe, vì vậy chúng tôi đã tìm kiếm một công cụ hiện có có thể thực hiện công việc nâng đỡ nặng nhọc cho chúng tôi.
Quản lý vòng đời ảnh chụp nhanh (SLM)
Công cụ đầu tiên chúng tôi đã thử là quản lý vòng đời Ảnh chụp nhanh (SLM) của Elastic, một tính năng được mô tả là:
Cách dễ nhất để thường xuyên sao lưu một cụm. Chính sách SLM tự động chụp ảnh nhanh theo lịch trình đặt trước. Chính sách cũng có thể xóa ảnh chụp nhanh dựa trên các quy tắc lưu giữ mà bạn xác định.
Bạn thậm chí có thể sử dụng kho lưu trữ ảnh chụp nhanh của riêng mình. Tuy nhiên, ngay sau khi chúng tôi cố gắng thiết lập điều này trong các miền của mình, nó không thành công. Chúng tôi nhanh chóng biết rằng AWS ES là một phiên bản sửa đổi của Elastic. ES của co và SLM đó không được hỗ trợ trong AWS ES.
Giám tuyển
Công cụ tiếp theo mà chúng tôi điều tra được gọi là Elasticsearch Curator. Nó là mã nguồn mở và được duy trì bởi chính Elastic.co.
Người quản lý chỉ đơn giản là một công cụ Python giúp bạn quản lý các chỉ số và ảnh chụp nhanh của mình. Nó thậm chí còn có các phương thức trợ giúp để tạo kho lưu trữ ảnh chụp nhanh tùy chỉnh, đây là một phần thưởng bổ sung.
Chúng tôi quyết định chạy Curator dưới dạng một hàm Lambda được điều khiển bởi quy tắc EventBridge đã lên lịch, tất cả đều được đóng gói trong AWS SAM.
Đây là giải pháp cuối cùng trông như thế nào:
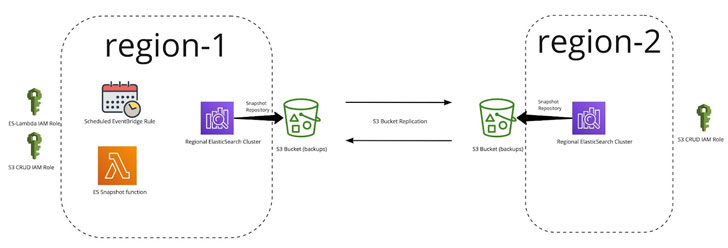
ES Snapshot Lambda Chức năng
Lambda sử dụng công cụ Người quản lý và chịu trách nhiệm quản lý ảnh chụp nhanh và kho lưu trữ. Đây là sơ đồ logic:
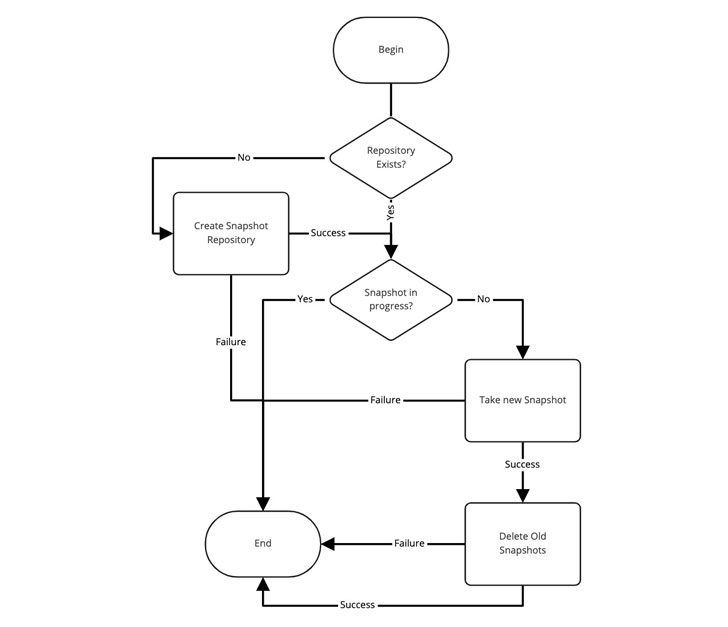
Như bạn có thể thấy ở trên, đó là một giải pháp rất đơn giản. Tuy nhiên, để nó hoạt động, chúng tôi cần một vài thứ tồn tại:
Vai trò IAM để cấp quyền Một nhóm S3 có bản sao sang vùng khác Một miền Elasticsearch với các chỉ mục
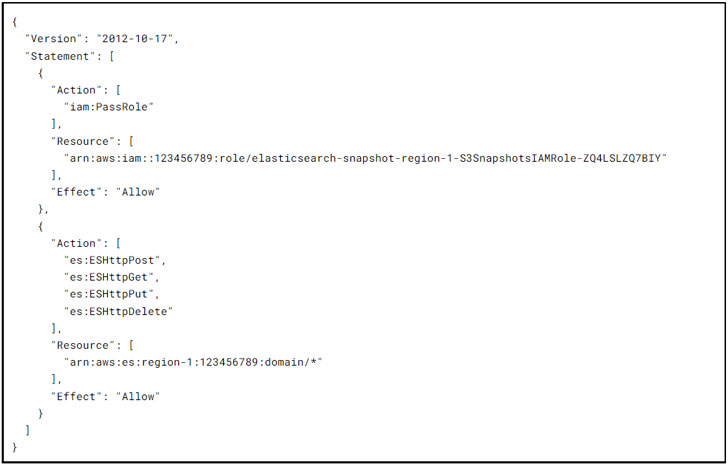
Vai trò IAM
S3SnapshotsIAMRole cấp cho người quản lý các quyền cần thiết để tạo kho lưu trữ ảnh chụp nhanh và tự quản lý các ảnh chụp nhanh thực tế:

EsSnapshotIAMRole cấp cho Lambda các quyền mà người quản lý cần để tương tác với miền Elasticsearch:
Nhóm S3 được tái tạo
Nhóm nghiên cứu trước đó đã thiết lập các nhóm S3 nhân rộng cho các dịch vụ khác để tạo điều kiện nhân rộng vùng xuyên suốt trong Terraform. (Thông tin thêm về điều đó ở đây)
Với mọi thứ đã sẵn sàng, ngăn xếp thông tin đám mây được triển khai trong thử nghiệm ban đầu sản xuất đã diễn ra tốt đẹp và chúng tôi đã hoàn thành… hay là chúng tôi?

Sao lưu và Khôi phục-a-thon I
Một phần của chứng nhận SOC2 yêu cầu bạn xác nhận các bản sao lưu cơ sở dữ liệu sản xuất của mình cho tất cả các dịch vụ quan trọng. Bởi vì chúng tôi muốn có một số niềm vui, chúng tôi quyết định tổ chức “Sao lưu và khôi phục-a-thon” hàng quý. Chúng tôi giả định rằng khu vực ban đầu đã biến mất và chúng tôi phải khôi phục từng cơ sở dữ liệu từ bản sao giữa các khu vực của chúng tôi và xác thực nội dung.
Người ta có thể nghĩ “Ôi trời, thật là nhiều công việc không cần thiết!” và bạn sẽ đúng một nửa. Đó là rất nhiều công việc, nhưng nó là hoàn toàn cần thiết! Trong mỗi lần Restore-a-thon, chúng tôi đã phát hiện ra ít nhất một vấn đề với các dịch vụ không bật tính năng sao lưu, không biết cách khôi phục hoặc truy cập vào bản sao lưu đã khôi phục. Chưa kể đến việc đào tạo thực hành và kinh nghiệm mà các thành viên trong nhóm có được thực sự làm một điều gì đó không dưới áp lực cao của sự cố ngừng hoạt động thực sự. Giống như chạy một cuộc diễn tập chữa cháy, Restore-a-thons hàng quý của chúng tôi giúp nhóm của chúng tôi luôn chuẩn bị và sẵn sàng xử lý mọi trường hợp khẩn cấp.
ES Restore-a-thon đầu tiên diễn ra vài tháng sau khi tính năng này hoàn thành và được triển khai trong quá trình sản xuất nên đã có nhiều ảnh chụp nhanh được chụp và nhiều ảnh cũ bị xóa. Chúng tôi đã định cấu hình công cụ để giữ các ảnh chụp nhanh có giá trị trong 5 ngày và xóa mọi thứ khác.
Bất kỳ nỗ lực nào để khôi phục ảnh chụp nhanh được sao chép từ kho lưu trữ của chúng tôi đều không thành công với một lỗi không xác định và không còn nhiều điều khác để tiếp tục.
Ảnh chụp nhanh trong ES tăng dần có nghĩa là tần suất ảnh chụp nhanh càng cao thì chúng hoàn thành nhanh hơn và kích thước chúng càng nhỏ. Ảnh chụp nhanh ban đầu cho miền lớn nhất của chúng tôi mất hơn 1,5 giờ để hoàn thành và tất cả các ảnh chụp nhanh hàng ngày tiếp theo chỉ mất vài phút!
Quan sát này đã khiến chúng tôi cố gắng bảo vệ ảnh chụp nhanh ban đầu và ngăn nó bị xóa bằng cách sử dụng hậu tố tên (-initial) cho ảnh chụp nhanh đầu tiên được chụp sau khi tạo kho lưu trữ. Sau đó, tên ảnh chụp nhanh ban đầu đó bị Người quản lý loại trừ khỏi quy trình xóa ảnh chụp nhanh bằng cách sử dụng bộ lọc regex.
Chúng tôi đã xóa các nhóm, ảnh chụp nhanh và kho lưu trữ S3 và bắt đầu lại. Sau khi đợi vài tuần để tích lũy các ảnh chụp nhanh, quá trình khôi phục lại không thành công với cùng một lỗi khó hiểu. Tuy nhiên, lần này chúng tôi nhận thấy ảnh chụp ban đầu (mà chúng tôi đã bảo vệ) cũng bị thiếu!
Không còn chu kỳ nào để chi tiêu cho vấn đề, chúng tôi phải đặt nó để làm việc với những điều thú vị và tuyệt vời khác mà chúng tôi đang thực hiện ở đây tại Rewind.
Sao lưu và Khôi phục-a-thon II
Trước khi bạn biết điều đó, quý tiếp theo bắt đầu và đó là thời gian cho một Sao lưu và Khôi phục khác và chúng tôi nhận ra rằng đây vẫn là một lỗ hổng trong kế hoạch khắc phục thảm họa của chúng tôi. Chúng tôi cần có thể khôi phục thành công dữ liệu ES ở một vùng khác.
Chúng tôi quyết định thêm ghi nhật ký bổ sung vào Lambda và kiểm tra nhật ký thực thi hàng ngày. Ngày 1 đến ngày 6 đang hoạt động hoàn toàn tốt – khôi phục công việc, chúng tôi có thể liệt kê tất cả các ảnh chụp nhanh và ảnh ban đầu vẫn ở đó. Vào ngày thứ 7, một điều kỳ lạ đã xảy ra – lệnh gọi để liệt kê các ảnh chụp nhanh có sẵn trả về lỗi “không tìm thấy” chỉ cho ảnh chụp nhanh ban đầu. Thế lực bên ngoài nào đang xóa những bức ảnh chụp nhanh của chúng ta ??
Chúng tôi quyết định xem xét kỹ hơn nội dung nhóm S3 và thấy rằng đó là tất cả các UUID (Định danh duy nhất toàn cầu) với một số đối tượng tương quan với ảnh chụp nhanh ngoại trừ ảnh chụp nhanh ban đầu bị thiếu.
Chúng tôi nhận thấy nút chuyển đổi “hiển thị phiên bản” trong bảng điều khiển và nghĩ rằng thật kỳ lạ khi nhóm đã bật lập phiên bản trên đó. Chúng tôi đã bật chuyển đổi phiên bản và ngay lập tức thấy “Xóa điểm đánh dấu” ở khắp nơi, bao gồm cả một điểm trên ảnh chụp nhanh ban đầu đã làm hỏng toàn bộ bộ ảnh chụp nhanh.
Trước và sau
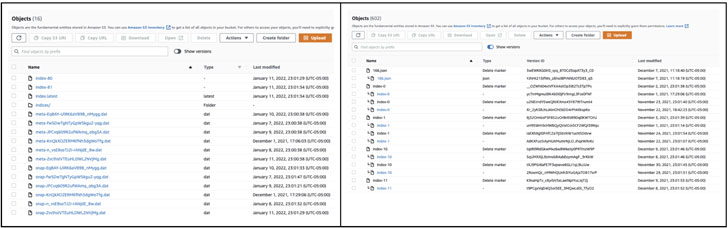
Chúng tôi rất nhanh chóng nhận ra rằng thùng S3 mà chúng tôi đang sử dụng có quy tắc vòng đời 7 ngày để xóa tất cả các đối tượng cũ hơn 7 ngày.
Quy tắc vòng đời tồn tại để các đối tượng không được quản lý trong nhóm sẽ tự động được xóa để giảm chi phí và ngăn nắp.

Chúng tôi đã khôi phục đối tượng đã xóa và thì đấy, danh sách các ảnh chụp nhanh hoạt động tốt. Quan trọng nhất, việc khôi phục đã thành công.
Căng nhà
Trong trường hợp của chúng tôi, Người phụ trách phải quản lý vòng đời của ảnh chụp nhanh, vì vậy tất cả những gì chúng ta cần làm là ngăn quy tắc vòng đời xóa bất kỳ thứ gì trong kho lưu trữ ảnh chụp nhanh của chúng tôi bằng cách sử dụng bộ lọc đường dẫn theo phạm vi trên quy tắc.
Chúng tôi đã tạo một tiền tố S3 cụ thể được gọi là “/ auto-purge” mà quy tắc được áp dụng. Mọi thứ cũ hơn 7 ngày trong / auto-purge sẽ bị xóa và mọi thứ khác trong nhóm sẽ được giữ nguyên.
Chúng tôi đã dọn dẹp mọi thứ một lần nữa, đợi> 7 ngày, chạy lại quá trình khôi phục bằng cách sử dụng các ảnh chụp nhanh được sao chép, và cuối cùng nó hoạt động hoàn hảo – Sao lưu và Khôi phục-a-thon cuối cùng đã hoàn thành!

Sự kết luận
Lên một kế hoạch phục hồi sau thảm họa là một bài tập tinh thần khó khăn. Việc triển khai và kiểm tra từng phần của nó thậm chí còn khó hơn, tuy nhiên đó là một thực tiễn kinh doanh cần thiết để đảm bảo tổ chức của bạn có thể vượt qua mọi cơn bão. Chắc chắn, cháy nhà là điều khó xảy ra, nhưng nếu nó xảy ra, bạn có thể sẽ rất vui vì đã thực hành những việc cần làm trước khi khói bắt đầu bốc lên.
Đảm bảo hoạt động kinh doanh liên tục trong trường hợp nhà cung cấp ngừng hoạt động cho các bộ phận quan trọng của cơ sở hạ tầng của bạn đặt ra những thách thức mới nhưng nó cũng mang lại cơ hội tuyệt vời để khám phá các giải pháp như giải pháp được trình bày ở đây. Hy vọng rằng, cuộc phiêu lưu nhỏ của chúng tôi ở đây sẽ giúp bạn tránh được những cạm bẫy mà chúng tôi phải đối mặt khi đưa ra kế hoạch khắc phục thảm họa Elasticsearch của riêng bạn.
Lưu ý – Bài viết này được viết và đóng góp bởi Mandeep Khinda, Chuyên gia DevOps tại Rewind.
.
